
这个权当学习MIT6.S184的总结性学习笔记了。强推这门课程,课程体量不大,但是设计非常用心,从头到尾、从理论到实践讲解了现代常用图像生成模型-Diffusion Model and Flow Model的原理和实现。具体内容可以参考课程官网。大概20-30小时就可以完成这门课程的全部内容。
Diffusion Model and Flow Model
作为工业界视频和图片生成的主流模型,Diffusion Model和Flow Model兼具复杂的数学原理以及简单的训练逻辑。想要把握住二者的平衡并不容易,因此我尝试在这里梳理出基于扩散和流的生成模型从原理到算法实现的主体脉络。本文主要目的在于动机和基本步骤的介绍,略去了数学证明和实现细节。
理解 Distribution of images
首先我们需要尝试把生成图片这个复杂的过程抽象为一个数学过程。
这里我们可以把一张图片视作一个高维$H\times W\times C$的空间中的一个点。世界上所有的图片都可以视作这个空间中的点。显然,我们见过的所有正常图片在这个空间中都有一定的分布规律与聚集规律,而不是随机分布的。因此我们就可以建立一个抽象的分布模型$p_{data}$,这个模型实现了从$R^{H\times W \times C}\to R\in[0,1]$的一个映射。
然而由于这个空间太大了,我们完全无法写出$p_{data}$的显式表达式,这是现实世界分布过于复杂带来的必然情况。但是这个$p_{data}$有一个先天而来的优势,就是我们可以轻松的从中采样,$z_1,\dots,z_n$。
这就为我们带来了相应的灵感:可不可以构建这样的一个生成模型,它模拟了$p_{data}$的分布。每次我们使用它生成图片,都相当于从$p_{data}$采样。也就是说给定一个输入图片$X\sim N(0,I_d)$,经过生成模型加工之后,得到了$Z\sim p_{data}$。(PS:这里之所以要采取高斯噪音作为初始输入的理论基础涉及信息论中熵部分的内容,同时这也是一个久经验证的工业常识了)。
如果把握住了上面的动机,就可以正式开始构建我们的生成模型了。
定性理解 Diffusion 和 Flow 模型
最近我们常用的各种图片和视频生成模型(已经去世的Sora,Nano Banana,Seedance等)都是基于diffusion或者flow模型框架基础设计的,它们在现实应用中已经获得了比较好的效果。然而在diffusion和flow横空出世之前,业界的主流是GAN模型。GAN模型有着较快的生成速度,但是生成效果相对较差,存在伪影,面对客户各种各样的要求的泛化能力比较差,这也是one-step方法面对复杂的高维的图像难以避免的问题。因此科研人员提出了来源于物理世界的diffusion(扩散)和flow(流)模型,在step-by-step中不断更新生成的图片。
尽管在学术界的是扩散模最先得到发展的是扩散模型,但是从理解的角度来说按照先flow后diffusion的方式会更直观一点。
Flow Model
不妨想象这样的情景:把一艘小纸船放到一个水池里,水池的中心有一个漩涡,那么我们可以知道这个小纸船会不断地转圈向漩涡中心靠近,直到被吸入漩涡中心。定性地讲,这里涉及两个定义:一个是运动轨迹,即小纸船在$t$时刻所处的位置,在这个情境中是二维的$(x,y)$,还有一个是速度方向,也就是向量场,说明小纸船在当前位置$(x,y)$以及时刻$t$的速度方向$(v_x,v_y)$。
如何离散化地表达这个过程?这里我们使用最简单的方式,也就是显式欧拉法。
$$ X_{t+h} = X_t + h u_t(X_t)$$尽管在物理仿真中显式欧拉法的效果很差,但是在我们今天讨论的流模型和扩散模型中,它的效果是足够好的。
我们可以把生成图片的step-by-step过程视作是上面的情形。小纸船的位置,就是我们想要生成的那张图片在$t$时刻的状态,只不过现在是一个高维的向量,每一位都是图片的像素值。而图片的速度方向,即向量场,决定了图片中的像素值要怎么改变。我们的生成模型的目标,就是使用深度学习的方式训练出一系列向量场,使得输入噪音图片在向量场的作用下一点点变化,最后生成我们想要的、符合现实世界分布的图片。
Diffusion Model
相比于宏观角度的Flow Model,Diffusion Model更多是借鉴了布朗运动的一些内容进行建模。这里我们略去复杂的推导,给出最终的表达式:
$$X_{t+h}=X_t +hu_t(X_t)+\sigma_t \sqrt{h} \epsilon,\epsilon\sim N(0,I_d)$$可以看到相比于流模型,扩散模型多出了一个随机项,其中$\sigma_t$是扩散系数,至于其合理性,就交给物理学家以及分子学家来解释了。
可以发现我们现在的探讨还是停留于抽象的意识流层面,在前面我们已经提到了,没有任何方法去显式地表达$p_{data}$,所以即使我们想要构建一个向量场来引导图片,我们也不知道我们的终点$p_{data}$到底是什么。
如何解决这种不可定量计算描述的困局?
这个概率论的问题对于聪明的数学家们来说还是太简单了,这里我们引入四个重要的概念。
Conditional Prob Path
首先引入Probablity Path,可以把它理解成为一个随时间不断变化的分布。由于$p_{data}$不可知,因此我们无法求出$p_{data}(X)$,然而如果我们把最终生成的图像限于一张图片$Z$,我们最终的目标就确定了,这样的话我们的对输入图片$X$的引导的计算表述难度就大大地降低了。
给出定义:
Dirac Distribution
$$ \delta_z: X \sim \delta_z \iff X=z $$这个分布意思很显然,无论取样多少次,都只会产生一个固定的结果$z$。
所以我们可以把向量场的目标设定为:让$X$变成$z$。用相对严谨的术语表达为:
Conditional Probability Path
- 满足任意一个时刻的$P_t(x|z)$本身满足概率分布的性质
- $P_0(x|z)=p_{init}$,与$z$无关
- $P_1(x|z)=\delta_z$
Marginal Prob Path
通过建立上面的条件概率路径模型,我们可以联想到概率统计里面学习到的边缘概率,此处我们可以利用边缘概率的原理,来计算出$P_t(x)$。
$$P_t(x)=\int p_t(x|z)p_{data}(z)dz$$从离散的角度,我们可以理解为从$p_{data}$中不断取样,然后对不同的条件概率求平均值。
Insights:可以把Prob Path视作从$p_{init}$到$p_{data}$的插值逼近过程
Conditional Vector Field
Prob Path定义了关于“走什么样的路线”的问题,而Vector Field则回答了“如何走出预定路线”的问题。
$$ X_0\sim p_{init},\frac{d}{dt}X_t=u_t(X_t|z) \Rightarrow X_t\sim p(\cdot|z) $$Marginal Vector Field
同理,当我们获得了对于每个特定的条件点$z$的CVF之后,也可以求出对应的MVF。但是值得注意的是,这里的公式相比于Prob Path部分,并不是那么non-trivial的。
我们不妨先来简单地定性分析一下MPP那个积分式:$x$游走于高维空间中,高维空间中有很多满足图片特征分布的目标点$z$,$x$走的路径就是以任何一个$z$为目标点的时候的路径的按概率加权平均。
而对于MFV,我最初的想法是,那就用相同的方法算不就得了?但是后来发现事情没有这么简单。这里涉及到一些数学连续性上的推导,我们直接省略,给出最终的定义。
$$ \begin{aligned} u_t(x)&=\int u_t(x|z)\frac{p_t(x|z)p_{data}(z)}{p_t(x)}dz \\ &=\int u_t(x|z) p(z|x)dz \end{aligned} $$定性理解就是,我们现在要考虑的是,在当前的位置$x$条件下,有多大的概率能到达$z$?这决定了我们给对应的向量场分配的权重。
给出了这几个基本的定义之后,我们就成功实现了把一个抽象的不可计算不可建模的问题转化成了可计算可建模的问题。下面我们来进一步给这个过程施加更多约束,来简化这个建模。
Gassuian Prob Path
或许一个最朴素的想法:我们可以让Prob Path服从高斯分布?
$$ P_t(\cdot|z)=N(\alpha_tz,\beta_t^2I_d) $$其中$\alpha_t,\beta_t$被称为噪音系数,我们可以任意调整他们,只要可以满足$\alpha_0=\beta_1=0$且$\alpha_1=\beta_0=1$,即满足prob path定义的最低标准就可以了。常见的有$\alpha_t=t,\beta_t=1-t$。
在此定义上,经过数学运算,可以显式求出高斯条件向量场的表达式:
$$ \begin{aligned} u_t^{target}(x|z)=(\hat{\alpha}_t-\frac{\hat{\beta}_t}{\beta_t}\alpha_t)z+\frac{\hat{\beta}_t}{\beta_t}x\\ \hat{\alpha_t}=\partial_t{\alpha_t}\\ \hat{\beta_t}=\partial_t{\beta_t} \end{aligned} $$如果我们把$\alpha_t,\beta_t$设计的很简单,那么求完偏导之后上面那个看似复杂的式子也会变得简单很多。不然用$\alpha_t=t,\beta_t=1-t$试试?
Flow Matching and Score Matching
所以到底该如何使用深度学习的方法来求$u_t^{target}$? 如果你未曾学习过深度学习相关知识,可能需要修习一些入门课程才能理解这部分内容。 在我看来,深度学习的pipeline本质上是同构的,其整体框架都是三大块:输入、深度神经网络模型、输出。监督模型尤其如此。
- 输入:表格化数据、图片、音频、文字等等,一般会利用一些数据处理的方式把它们转为量化的可计算的数据形式。但是这里我们一般只进行数据清洗和数据转换,传统机器学习中常见的特征工程并不一定能带来好的效果。
- 深度神经网络模型(DNN):架构的核心部分。我们可以把它抽象为一个巨大的函数,由分层的线性函数和非线性函数构成。函数的类型本身已经定义好了,是hard-code的,但是函数的参数是需要在训练的过程中不断更新的。比方说$y=a_1x_1+a_2x_2$,这个函数本身是线性函数不可改变,但是$a_1,a_2$这两个权重是可以改变的。
- 输出:最终希望得到的结果。我们肯定希望模型输出的结果是好的,但是怎样算好?这就需要我们需要一个评判结果的标准,然后利用这个标准设置一个合理的可导的损失函数。随后利用反向传播和梯度下降对DNN部分的参数进行更新,来让模型输出的结果更好。
Flow Matching
- 训练目标:$u_t^{\theta}(x) = u_t^{target}(x)$ 这也就引出了我们的损失函数 $$ L_{FM}(\theta)=E[||u_t^{\theta}(x)-u_t^{target}(x)||^2] $$ 这是深度学习中很经典的MSE误差损失函数。然而问题在于,$u_t^{target}$这个东西我们是无法写出具体表达式的,只能通过不断抽样进行逼近。但是如果我们连目标都无法确定的话,那么训练就毫无稳定性可言,因此我们只能退而求其次,使用可以确定的条件向量场。
通过数学推导,可以计算出$L_{FM}(\theta)=L_{CFM}(\theta)+C$,那么这两个函数的梯度是一样的,因此在$L_{CFM}$上进行优化得到的最优值点$\theta^$可以满足我们$u_t^{\theta^}=u_t^{target}$的目标。
在实际训练的时候,这个看似复杂的求期望符号,其实已经被离散化消除掉了。由于要对$t,z,x$求期望,所以在每个回合中,先从图片数据集中取样一个$z$,再从均匀分布中取样一个$t$,最后根据$p(\cdot|z)$取样一个$x$,最后计算$L(\theta)=||u_t^{\theta}(x)-u_t^{target}(x|z)||^2$,然后进行反向传播和对参数的梯度下降更新即可。
读者可以尝试把高斯概率路径的一系列公式代入。
Score Matching
还记得我们之前说到的Diffusion Model吗?由于扩散模型是基于SDE的演化路径的,所以要比Flow Model复杂很多。
在流模型的ODE场景下,想让图片$x$演变为$z\sim p_{data}$只需满足$dX_t=u_t^{target}(X_t)dt$就可以最终$X_t\sim P_t$了。
但是在扩散模型的SDE场景下,我们在路径中加入了噪声扰动,然而这噪声扰动对最终结果的分布也是有影响的,因此需要从数学上纠正噪声来保证实现目标Prob Path。
数学家高手们定义了Score Function,满足$S_t(X)=\nabla_x \log P_t(x)$,这个函数可以满足:
$$ \begin{aligned} X_0 &\sim P_{init} \\ dX_t&= u_t^{target(X_t)}dt+\frac{1}{2}\sigma_t^2S_t(X_t)dt + \sigma_t dW_t \\ \Rightarrow X_t&\sim P_t \end{aligned} $$其中$W_t$的具体定义就不赘述了,大家可以把它理解为一个高斯扰动。
但你可能会疑惑,好了好了,这下好了,原来只需要训练一个$u_t^{\theta}$,现在还得再多训练一个$S_t^{\theta}$,这不没事找事吗?
所以这里不得不说清楚SDE的优势到底在哪里:
- 扩散 SDE 的反向过程每一步都注入适量噪声。当数值求解引入误差(比如步长过大导致轨迹偏离)时,这种随机扰动会把样本重新推向高概率区域,相当于在采样中自动纠错。
希望这可以说服你,如果不能,也无所谓,因为现在主流确实是速度更快更简单的Flow Matching,但是从方法的出现顺序上来看其实是基于添加噪声的Score Matching出现的更早。
同时,在常用的高斯路径中,通过数学推导可以实现$u_t$和$S_t$的相互表示,这里就不赘述了,可以直接参考讲义中的数学公式(我也懒得敲了)。
在实际训练中基本逻辑和Flow Matching一致,只需要让程序模拟离散版本的SDE就行了。
Guidance:Condition on a Prompt
我们训练生成模型的本意肯定不是为了搞出来一个你按一下按钮然后就蹦出来一张图片的机器塞博斗蛐蛐用,我们肯定希望生成的图片能够满足一定的要求,而表达这种要求最自然的方式就是:语言。不妨将它记为一个抽象的符号$y$,意为guidance/prompt。
现在的问题变得奇妙起来了,我们不仅仅需要生成的图片是一张人类能够正常理解的真实的图片,更重要的是我们需要这个图片是满足我们最初用任何prompt方式表达的要求的一张图片。也就是说我们需要在评判标准里加上一项来评定生成的图片与prompt的相符程度。
Vanilla Guidance
最朴素的方式就是直接给每种标签或者prompt对应训练一个向量场$u_t^{\theta}(x|y)$。 然后按照
$$L_{CFM}=E_{t\sim[0,1],(z,y)\sim p_{data},x}[||u_t^{\theta}(x|y)-u_t^{target}(x|z)||^2] $$进行相应的优化。
然而在实际应用过程中发现这种方法生成的图片的效果不是太好,往往出现不是太遵守prompt限制这一问题。
Classifier Guidance
为了让生成的图片能够更好地去满足prompt的要求,我们考虑加入一个分类器:$p_t(y|x)$,即我们希望生成的图片能够被分类器判断为对应的标签。
利用一系列数学推导,可以得出:
$$u_t^{target}(x|y)=u_t^{target}(x)+a_t\nabla \log p_t(y|x)$$也就是我们从数学上严谨地证明了,在Prompt限制下的向量场可以表示为原始的无条件向量场与分类器梯度的矢量和。 这部分证明其实是用到了不少的trick以及前面的知识的,有兴趣的读者可以自己尝试推导,如果懒得推的就记住条件向量场由无条件向量场和分类器梯度求和而得到。
为了更进一步体现出Guidance,我们考虑加大分类器梯度的权重。
$$u_t^w(x|y)=u_t^{target}(x)+wa_t\nabla_x \log p_t(y|x)$$但是问题来了,这里的分类器,其实是我们在视觉领域一直喜闻乐见的入门任务:图像分类,但是这也就说明我们不仅需要去尝试训练一个向量场$u_t(x)$,还需要单独训练一个分类器,能不能通过数学运算把这个分类器的训练省去呢?
Classifier-free Guidance
还真可以。利用
$$\nabla \log p_t(x|y)=\nabla p_t(x) + \nabla p_t(y|x)$$进行替换,得到
$$u_t^w(x|y)=wu_t^{target}(x|y)+(1-w)u_t^{target}(x)$$?这不还是得训练两个model吗?你说得对,但是强大的研究人员们使用了一个小trick。我们不妨把$u_t(x)$视作$u_t(x|\emptyset)$,其中$\emptyset$就是人造的新标签。虽然训练集中可能所有图片都有标签,但是我们只需要随机选出一小部分把它们的标签设置为$\emptyset$就可以开始跑训练了。真是神之一手啊!
所以自此我们的最终目标就变成为训练一个$u_t^{\theta}(x|y)$。然后在生成的过程中使用classifier-free Guidance。
$$u_t^w(x|y)=wu_t^{target}(x|y)+(1-w)u_t^{target}(x|\emptyset)$$细心的你已经发现了,这个东西看起来很好,但是实操的时候,我们可以很轻松地表示出高斯路径下的$u_t^{target}(x|z)$,但是这个$u_t(x|y)$呢?难道我们真的要每种标签y都对应练一个向量场?那这样的话如果面对复杂的语境、没见过的标签不久没法泛化了吗?所以必须得想个办法把$y$进行处理,比如某种embedding方式,或者特殊化设计神经网络的结构。这是后文的内容。
Build a Conditional Generative Model for Images
到现在为止,我们已经基本上完成了基于流和扩散的生成模型的理论的学习,如果你只是为了了解一下现代图像生成模型的简单原理,那么看到这里就可以了。 但是,任何理论和实践之间,都有着巨大的鸿沟。而demo类型的实践和工业级别的实践更有着巨大的鸿沟。为了达成理论推导下可行的目标,我们往往需要探索比底层理论更多、更复杂、甚至更加高深的实践细节。而MIT6.S184的作业三正是给我们提供了一个完整的框架,让我们体会如何从零到一搭建起一个在MNIST数据集上训练的demo级别的图片生成模型。如果你已经做过了这个作业,你会发现这个作业远远比作业一和作业二那种单纯可视化概念的题目要难很多。
References:
- William Peebles and Saining Xie. Scalable Diffusion Models with Transformers. 2023. arXiv: 2212 . 09748 [cs.CV]. url: https://arxiv.org/abs/2212.09748.
- Robin Rombach et al. High-Resolution Image Synthesis with Latent Diffusion Models. 2022. arXiv: 2112.10752 [cs.CV]. url: https://arxiv.org/abs/2112.10752. 作业三的基础框架是基于上面两个论文搭建的,有兴趣的读者可以去看看论文里面的摘要和方法部分。
下面这一部分,我决定直接回归到lab3.ipynb,直接在对应的代码里通过注释来解释对应的细节。如果你自己在实现这部分代码的过程中(由于课程讲义中写的不是很清楚)出现了问题,可以参考
labnotes。
关于attention部分,我之前参考了3Blue1Brown的课程,绘制了一些基本的原理笔记,放在这里以供参考。
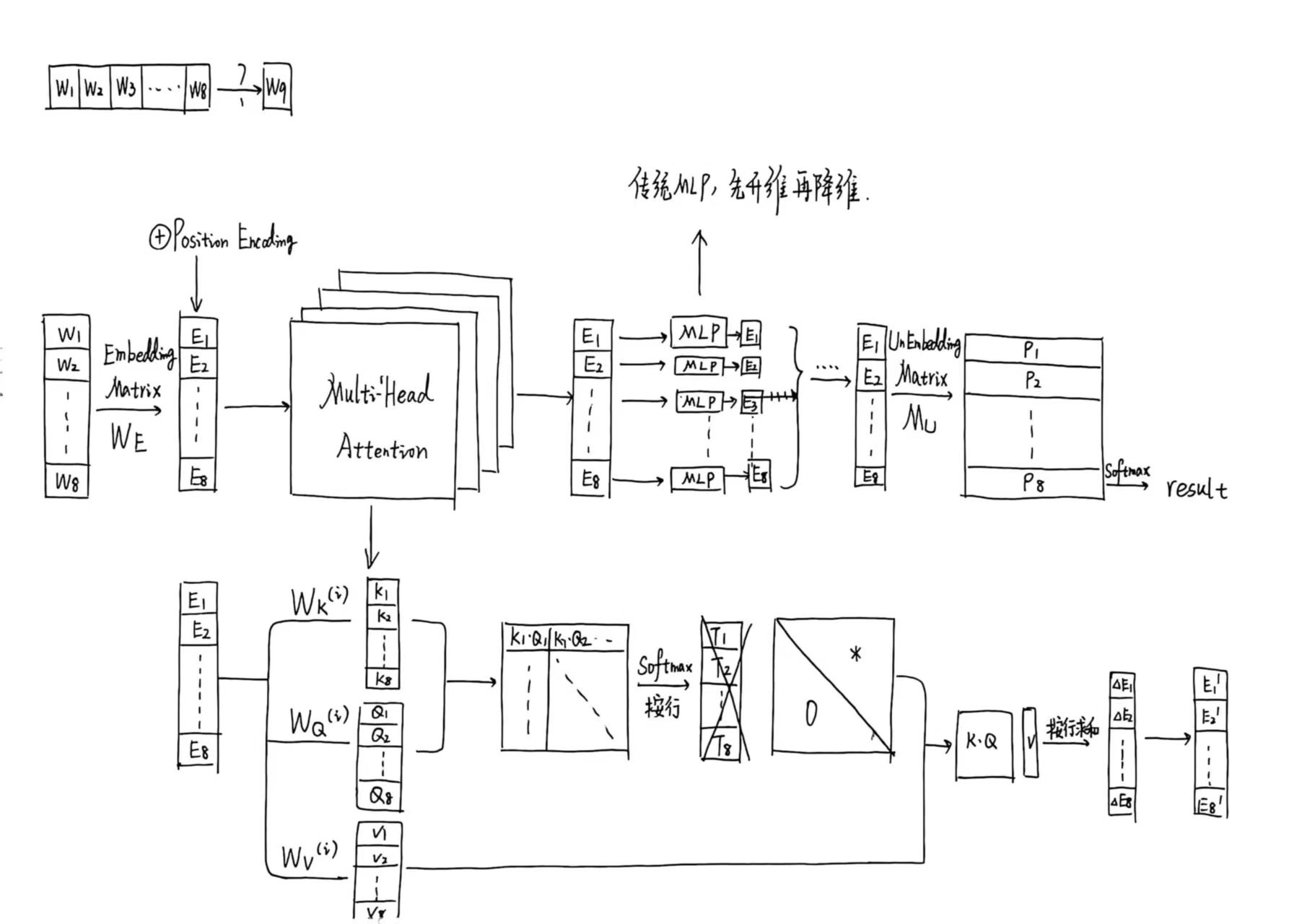
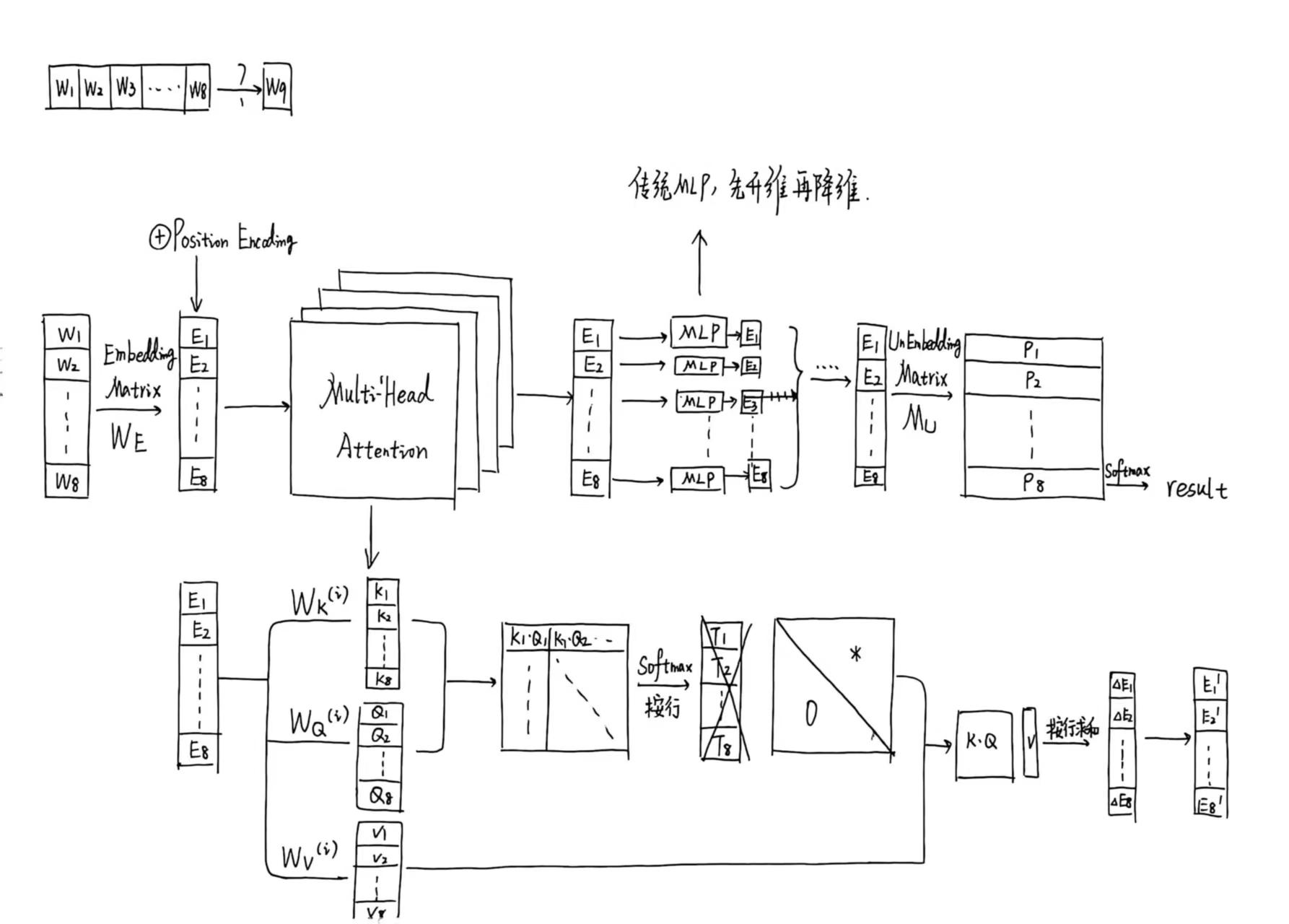

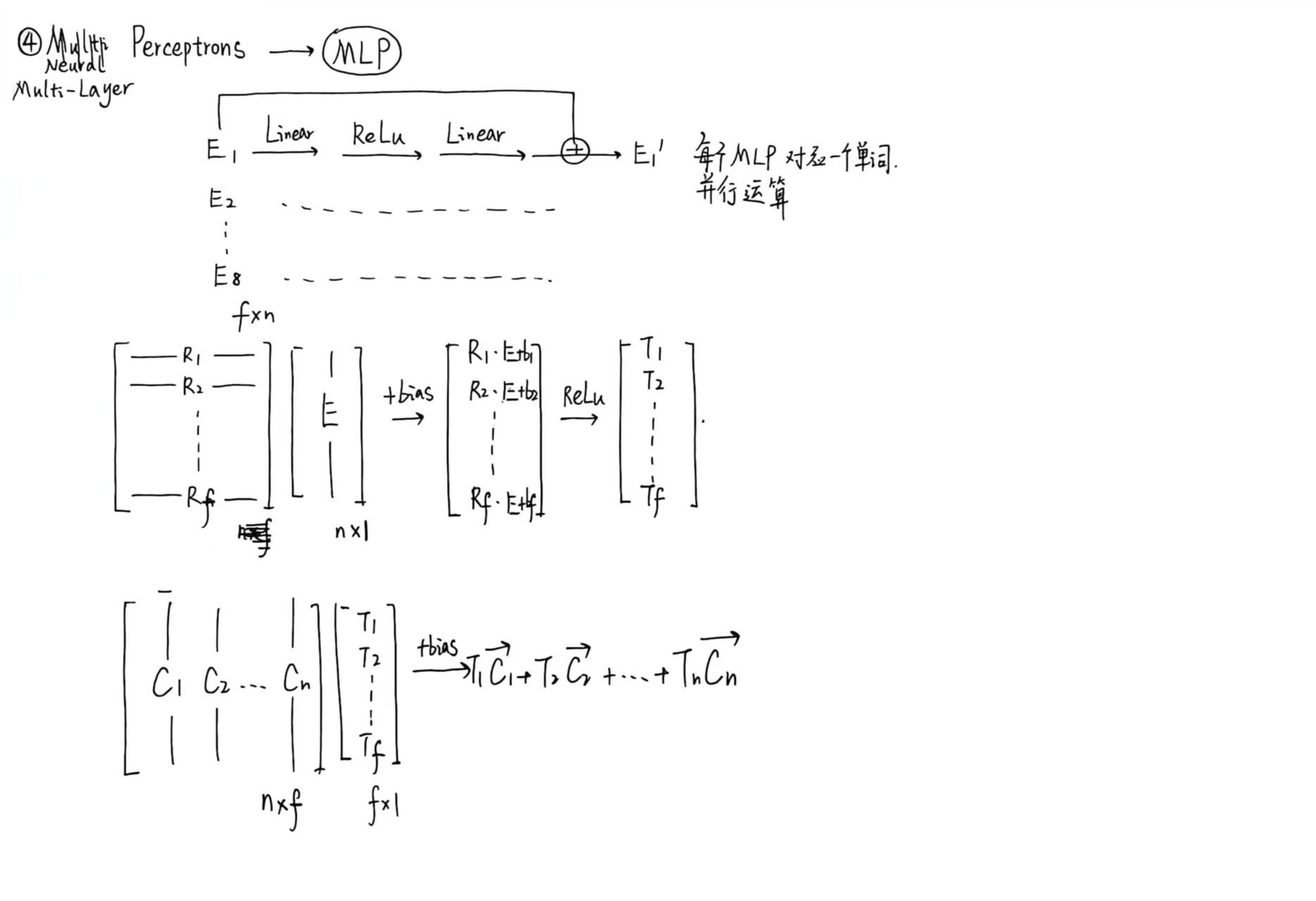

VAE
突然发现有一个重要的知识点Variational Auto Encoder没有写,所以得在这里补上。 在主流的图像生成模型中,由于一般想要生成的图像的像素数量太大了,会带来巨大的计算压力,因此我们考虑使用一个编码器,以某种方式把图像压缩到Latent Space,然后在这个Latent Space中对向量场进行相关计算训练,然后再把生成的图像通过一个解码器映射回原图的分辨率。
那么我们该如何设计相应的图像Encoder-Decoder呢?通常,VAE和扩散模型是分开训练的,而不是端到端直接训练的,这一方面是为了训练的稳定性,另外一方面由于VAE其实在其它图像处理任务中也有诸多应用,因此单独预训练一个还是很划算的。
那么我们从最naive的想法进入,encoder:$\mu_{\theta}:R^k \to R^d$,decoder$\mu_{\phi}:R^d \to R^k$,它们二者先后作用,理论上应该可以保持输入$x$不变。
$$L_{Recon}(\phi,\theta)=E_{x \sim p_{data}}[||\mu_{\theta}(\mu_{\phi}(x))-x||^2]$$这个想法很好,但是问题在于,这个方式更侧重编码器和解码器放在一起的效果,但是我们需要diffusion model跑在编码器生成的latent space的分布上,因此如果我们的编码器把$p_{data}$变成了一个很难训练的$p_{latent}$,那么最终的效果可能是不好的,所以我们需要人为加入一点heuristic启发式引导,给编码器生成的分布情况加上约束。
这里就可以介绍我们我们的Variational Autoencoder,即变分自编码器。看到variational这个词,不难想象的是相比于刚才介绍的标准方法,这种方法不再是确定性的映射,而转向了概率式的分布采样。
可能有些难以理解,我先把公式扔上来。
$$q_{\phi}(z|x)=N(z;\mu_{\phi}(x),diag(\sigma^2_{\phi}(x))),p_{\theta}(x|z)=N(x;\mu_{\theta}(z),\sigma^2_{\theta}(z)I_d)$$注意到,我们现在的编码器和解码器不是直接使用一个固定参数的网络实现映射,而是从正态分布里面采样,对应的正态分布的均值和方差才是神经网络参数化的内容。
这样的话,我们的生成模型的基本Pipeline就成型了,给定输入$x$,先编码采样$z\sim q_{\phi}(\cdot|x)$,然后把这个$z$扔到DiT里面一顿操作生成$z’$,再解码采样$x’\sim p_{\theta}(\cdot|z’)$获得最终生成的图像。
基本思路已经明确了,那么该如何训练这个VAE呢?首先就应该明确损失函数。
重建损失 这里的想法是,考虑经过编码之后的图片再扔进解码器之后能生成原图的置信度。
$$L_{VAE-Recon}(\phi,\theta)=-E_{x\sim p_{data}(x),z\sim q_{\phi}(\cdot|x)}[\log p_{\theta}(x|z)]$$
先验损失 这里就是为了解决我们在前面那部分提到的生成的latent space分布的先验约束问题,为了让这个分布变得容易训练,我们引入$p_{prior}(z)=N(0,I_k)$,我们的目标是让$q_{\phi}(z|x)$尽可能接近先验的标准正态分布。 为了衡量两个分布的相似性,我们常用的标准是KL-divergence,$D_{KL}(p(x)||q(x))=E_{X\sim p}[\log\frac{p(x)}{q(x)}]$。
$$K_{VAE-Prior}(\phi)=E_{x\sim p_{data}(x)}D_{KL}(q_{\phi}(\cdot|x)||p_{prior})$$
从而
$$L_{VAE}(\phi,\theta)=L_{VAE-Recon}(\phi,\theta)+\beta L_{VAE-Prior}(\phi)$$至于带入高斯分布之后的一些数学计算和简化就直接参考课程讲义就行了,这里就不赘述了。
最后这部分可能看起来相对零散,其实对于这种模型架构的时候,尤其是在作业中已经给了骨架代码的情况下,还是边写边学,比如写到一个地方不知道这部分代码在干嘛或者不知道具体该如何实现的时候去查阅资料,这样的效率更高一些。
至此,本文已经基本施工完毕。接下来我将开始学习MIT6.S978,尝试对生成模型有一个更全面且深入的了解。
当下即是最好。加油。頑張れ。